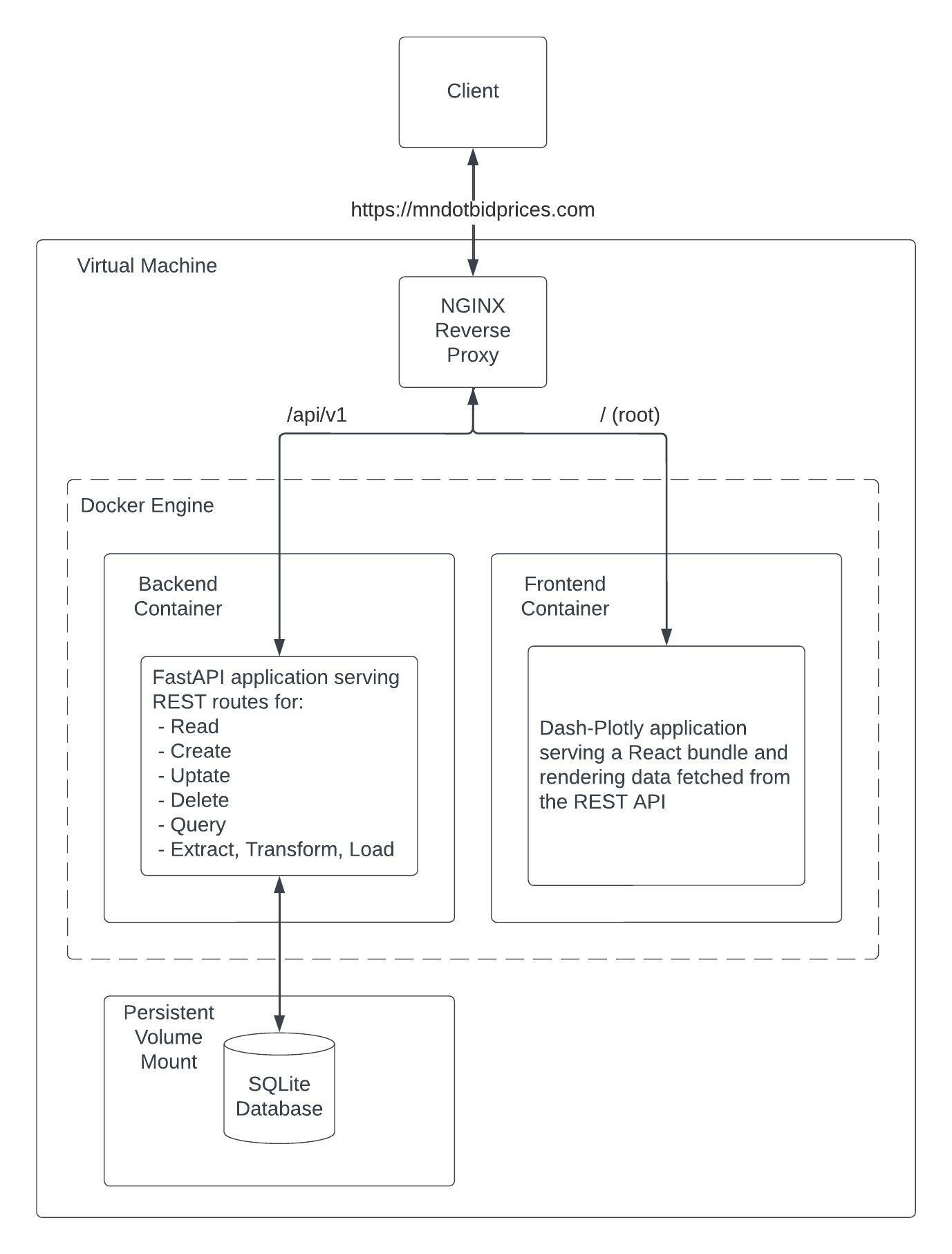
REST API
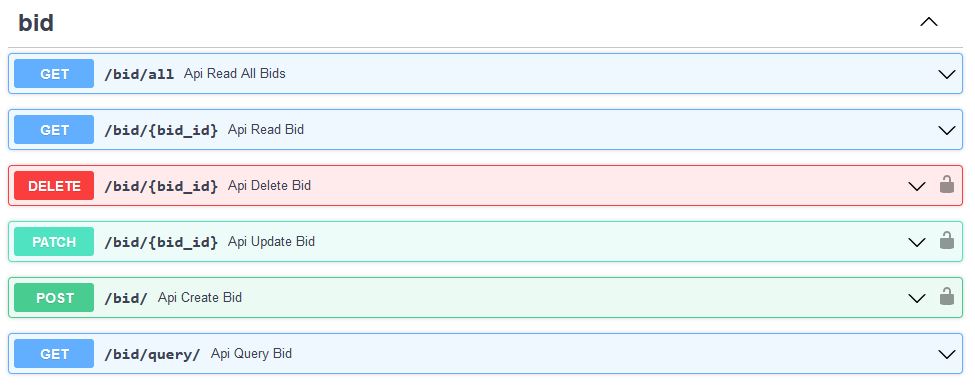
The backend was built using FastAPI to provide routing and operation layers in front of the database. The API provides create, read, update, delete, and query for each of the database tables for manually managing records. The API also provides two extract, transform, load routes that create or update records from data contained in item list and bid abstract CSVs downloadable from MnDOT's Transport List and Bid Letting Abstracts respectively.
Data Model
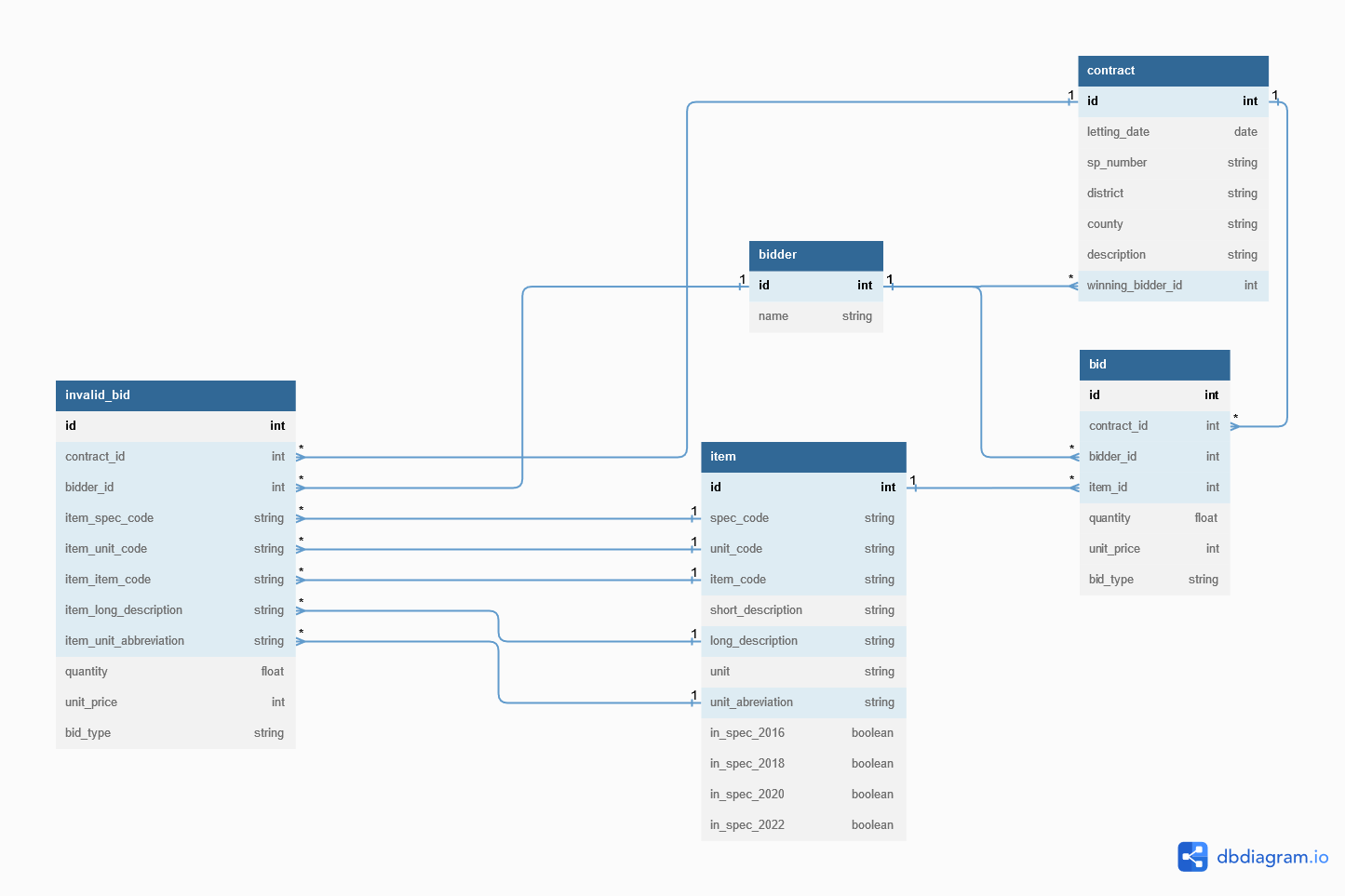
The data model was defined to closely reflect the content and organization of the source CSVs. This design allows records to be prepared for loading into the database with minimal transformation complexity. It also preserves the data as published allowing the backend to be mostly frontend agnostic.
Contract - General project data for a particular abstract
Bidder - Name and ID of prime contractors that have submitted a bid proposal that was ranked among the three lowest
Bid - Unit prices for each item including the engineer's estimate, winning bidder's price, and losing bidder's prices
Invalid Bid - Bid records for items that do not conform to items in the Transport List
Item - Items from the Transport List
Extract, Transform, Load
The ETL process is achieved through two critical libraries: Pandas and Pandera.
Pandas is used to read the uploaded CSV into DataFrames, transform the content of those DataFrames to match the schema of the destination database table, and iteratively pass those records to the appropriate create or update operation.
Pandera is a DataFrame validation library and plays a key role in verifying that the records loaded into the database through the ETL process conform to the desired schema. For each step in the process, a Pandera Schema Model is defined with custom validations to ensure that the intermediate data products contain all the requisite columns and proper types that the next step needs. Not only does this allow for defining predictable results from the transformations, but also enables broad error handling coverage so that the process can handle appropriately malformed inputs without crashing the server.